Autonomous Listening-Based Synthesizer Control with Reinforcement Learning for Live Sound Matching
Vincenzo Madaghiele; Stefano Fasciani; Tejaswinee Kelkar; Çağrı Erdem
- poster
- Presence: in person
- Type: long
- Session: Poster Session 3
Abstract:
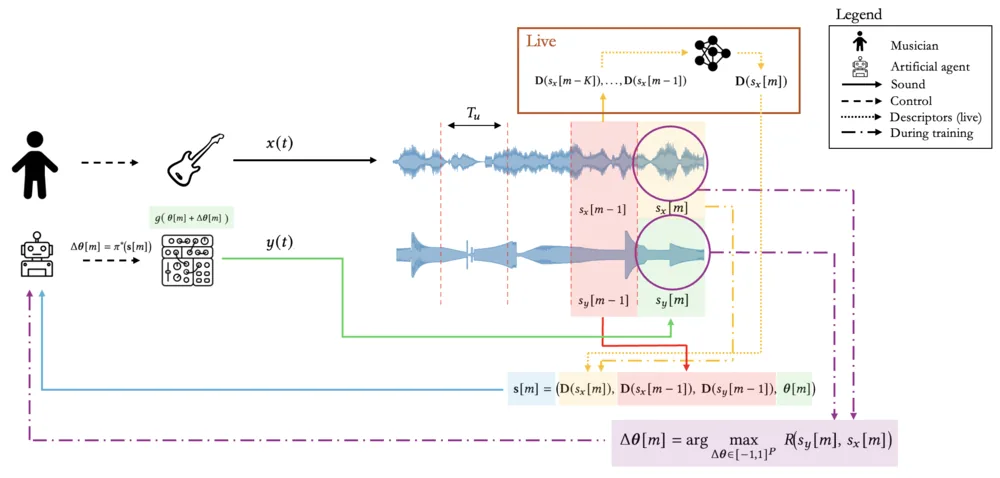
In this paper, we build on a previously proposed method for training an artificial agent that performs live control of sound synthesizers, using reinforcement learning and machine-listening to match the sound of a live musician. The agent listens to an incoming live audio stream and attempts to match its sound according to specific audio descriptors by controlling the parameters of an arbitrary synthesizer. We introduce a reinforcement_learning model with a continuous action space that integrates sound synthesis during training and live performance. We propose five complementary reward functions for matching target sounds, and evaluate their effectiveness in three scenarios: in_domain matching of synthesized target sounds, out_of_domain matching of synthesized targets, and out_of_domain matching using a corpus of musician_recorded audio. Finally, we compare the proposed reward functions across these scenarios, we discuss a live implementation and we present the results of quantitative experiments evaluating the matching task.